FAQ
What is Opacus?
Opacus is a library that enables training PyTorch models with differential privacy. It supports training with minimal code changes required on the client, has little impact on training performance and allows the client to online track the privacy budget expended at any given moment. Please refer to this paper to read more about Opacus.
Is Opacus open-source? What is the license?
Yes! Opacus is open-source for public use, and it is licensed under the Apache 2.0 license.
How can I report a bug or ask a question?
You can report bugs or ask questions by submitting GitHub issues. To submit a GitHub issue, please click here.
I'd like to contribute to Opacus. How can I do that?
Thank you for your interest in contributing to Opacus! Submit your contributions using GitHub pull requests here. Please take a look at Opacus contribution guide.
If I use Opacus in my paper, how can I cite it?
If you use Opacus in your papers, you can cite it as follows:
@article{opacus,
title={Opacus: {U}ser-Friendly Differential Privacy Library in {PyTorch}},
author={Ashkan Yousefpour and Igor Shilov and Alexandre Sablayrolles and Davide Testuggine and Karthik Prasad and Mani Malek and John Nguyen and Sayan Ghosh and Akash Bharadwaj and Jessica Zhao and Graham Cormode and Ilya Mironov},
journal={arXiv preprint arXiv:2109.12298},
year={2021}
}
What is DP-SGD?
DP-SGD is an algorithm described in this paper; Opacus is its Pytorch implementation. Please refer to this blog post to read more about DP-SGD.
How do I attach the privacy engine?
Training with Opacus is as simple as instantiating a PrivacyEngine and attaching it to the optimizer:
# define your components as usual
model = Net()
optimizer = SGD(model.parameters(), lr=0.05)
data_loader = torch.utils.data.DataLoader(dataset, batch_size=1024)
# enter PrivacyEngine
privacy_engine = PrivacyEngine()
model, optimizer, data_loader = privacy_engine.make_private(
module=model,
optimizer=optimizer,
data_loader=data_loader,
noise_multiplier=1.1,
max_grad_norm=1.0,
)
# Now it's business as usual
What is the secure_rng argument in PrivacyEngine?
Not all pseudo random number generators (RNGs) are born equal. Most of them (including Python’s and PyTorch’s default generators, which are based on the Mersenne Twister) cannot support the quality of randomness required by cryptographic applications. The RNGs that do qualify are generally referred to as cryptographically secure RNGs, CSPRNGs. Opacus supports a CSPRNG provided by the torchcsprng library. This option is controlled by setting secure_rng to True.
However, using a CSPRNG comes with a large performance hit, so we normally recommend that you do your experimentation with secure_rng set to False. Once you identify a training regime that works for your application (i.e., the model’s architecture, the right hyper parameters, how long to train for, etc.), then we recommend that you turn it on and train again from scratch, so that your final model can enjoy the security this brings.
My model doesn’t converge with default privacy settings. What do I do?
Opacus has several settings that control the amount of noise, which affects convergence. The most important one is noise_multiplier, which is typically set between 0.1 and 2. With everything else being constant, the standard deviation of the Gaussian noise is proportional to noise_multiplier, which means that scaling it down makes gradient computations more accurate but also less private.
The next parameter to adjust would be the learning rate. Compared to the non-private training, Opacus-trained models converge with a smaller learning rate (each gradient update is noisier, thus we want to take smaller steps).
Next one on the list is max_grad_norm . It sets the threshold above which Opacus clips the gradients, impairing convergence. Deeper models are less impacted by this threshold, while linear models can be badly hurt if their value is not set right.
If these interventions don’t help (or the model starts to converge but its privacy is wanting), it is time to take a hard look at the model architecture or its components. [Papernot et al. 2019] can be a good starting point.
How to deal with out-of-memory errors?
Dealing with per-sample gradients will inevitably put more pressure on your memory: after all, if you want to train with batch size 64, you are looking to keep 64 copies of your parameter gradients. The first sanity check to do is to make sure that you don’t go out of memory with "standard" training (without DP). That should guarantee that you can train with batch size of 1 at least. Then, you can check your memory usage with e.g. nvidia-smi as usual, gradually increasing the batch size until you find your sweet spot. Note that this may mean that you still train with small batch size, which comes with its own training behavior (i.e. higher variance between batches). Training with larger batch sizes can be beneficial. To this end, we built Fast Gradient Clipping and virtual_step (see what is virtual batch size in these FAQs) to make DP-SGD memory efficient.
What does epsilon=1.1 really mean? How about delta?
The (epsilon, delta) pair quantifies the privacy properties of the DP-SGD algorithm (see the blog post). A model trained with (epsilon, delta)-differential privacy (DP) protects the privacy of any training example, no matter how strange, ill-fitting, or perfect this example is.
Formally, (epsilon, delta)-DP statement implies that the probabilities of outputting a model W trained on two datasets D and D′ that differ in a single example are close:
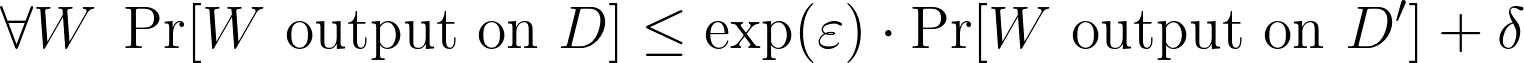 This statement extends to all downstream uses of this model: its inferences, fine-tuning, distillation, etc. In other words, if the (epsilon, delta)-DP property meets your privacy objectives, releasing the entire model—its architecture, weights, activation functions—is OK privacy-wise.
This statement extends to all downstream uses of this model: its inferences, fine-tuning, distillation, etc. In other words, if the (epsilon, delta)-DP property meets your privacy objectives, releasing the entire model—its architecture, weights, activation functions—is OK privacy-wise.
From the expression above it is obvious that epsilon and delta play different roles: epsilon controls the multiplicative increase in the baseline probability while delta lifts all probabilities by the same amount. For instance, if your baseline scenario (the model trained on D′, without your data) assigns 0 probability to some event, the bound on observing this event on D (that includes your data) is delta. Because of that, we’d like to target epsilon to be a small constant and select delta to be tiny. A rule of thumb is to set delta to be less than the inverse of the size of the training dataset.
Epsilon and delta are computed ex post, following an optimizer run. In fact, for each delta there’s some epsilon, depending on that delta, such that the run satisfies (epsilon, delta)-DP. The call privacy_engine.get_epsilon(delta=delta) outputs that epsilon in its first return value.
Importantly, (epsilon, delta)-DP is a conservative upper bound on the actual privacy loss. There’s growing evidence that the observable privacy loss of the DP-SGD algorithm can be significantly smaller.
How does batch size affect my privacy budget?
Assuming that batches are randomly selected, an increase in the batch size increases the sampling rate, which in turn increases the privacy budget. This effect can be counterbalanced by choosing a larger learning rate (since per-batch gradients approximate the true gradient of the model better) and aborting the training earlier.
My model throws IncompatibleModuleException. What is going wrong?
Your model most likely contains modules that are not compatible with Opacus. The most prominent example of these modules is batch-norm types. Before validating you model try to fix incompatible modules using ModuleValidator.fix(model) as described here.
What is virtual batch size?
Opacus computes and stores per-sample gradients under the hood. What this means is that, for every regular gradient expected by the optimizer, Opacus will store batch_size per-sample gradients on each step. To balance peak memory requirement, which is proportional to batch_size ^ 2, and training performance, we use virtual batches. With virtual batches we can separate physical steps (gradient computation) and logical steps (noise addition and parameter updates): use larger batches for training, while keeping memory footprint low. See the Batch Memory Manager for seamless integration into your training code.
What are alphas?
Although we report expended privacy budget using the (epsilon, delta) language, internally, we track it using Rényi Differential Privacy (RDP) [Mironov 2017, Mironov et al. 2019]. In short, (alpha, epsilon)-RDP bounds the Rényi divergence of order alpha between the distribution of the mechanism’s outputs on any two datasets that differ in a single element. An (alpha, epsilon)-RDP statement is a relaxation of epsilon-DP but retains many of its important properties that make RDP particularly well-suited for privacy analysis of DP-SGD. The alphas parameter instructs the privacy engine what RDP orders to use for tracking privacy expenditure.
When the privacy engine needs to bound the privacy loss of a training run using (epsilon, delta)-DP for a given delta, it searches for the optimal order from among alphas. There’s very little additional cost in expanding the list of orders. We suggest using a list [1 + x / 10.0 for x in range(1, 100)] + list(range(12, 64)).
A call to privacy_engine.get_epsilon(delta=delta) returns a pair: an epsilon such that the training run satisfies (epsilon, delta)-DP and an optimal order alpha. An easy diagnostic to determine whether the list of alphas ought to be expanded is whether the returned value alpha is one of the two boundary values of alphas.